Did you find this guide helpful?
Some test text!
Web
Guides
Web / Guides
Access PDF pages to add, copy, delete or rearrange using JavaScript
Make sure you have Full API enabled in WebViewer.
To access a PDF page.
async function main() {
const doc = await PDFNet.PDFDoc.createFromURL(filename);
// Access a PDF page
const page = await doc.getPage(page_num);
}
PDFNet.runWithCleanup(main);Merge, copy, delete, and rearrange PDF pages
Full code sample which illustrates how to copy pages from one document to another, how to delete, and rearrange pages and how to use ImportPages() method for very efficient copy and merge operations.
About working with pages
A high-level PDF document contains a sequence of Page objects, as illustrated in the following figure:
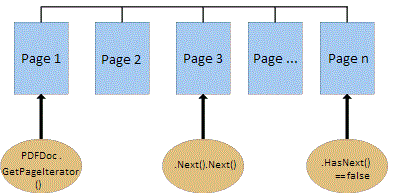
PDFDoc Page sequence.
To find the number of pages in a PDF document, call PDFDoc.GetPageCount().
To retrieve a specific page of a document, use PDFDoc.GetPage(page_num). Page numbers in the document's page sequence are indexed from 1. If the given page number doesn't index a page in the current document, GetPage(page_num) returns null. For example:
async function main() {
const page = await doc.getPage(page_num);
if (page != null)
{
console.log("Document does contain page#: %d", page_num);
}
else
{
console.log("Document does not contain page#: %d", page_num);
}
}
PDFNet.runWithCleanup(main);While GetPage(i) is convenient for retrieving an individual page, it's an inefficient way to enumerate every page of a document. It's better to traverse the pages with a PageIterator.
To do so, simply call PDFDoc.GetPageIterator(). This returns a PageIterator object, which provides HasNext(), Next() and Current() methods. The following code snippet shows how to print the page size for every page in document page sequence:
async function main() {
const itr = await doc.getPageIterator();
for (itr; await itr.hasNext(); itr.next())
{
const curritr = await itr.current();
const mediabox = curritr.getMediaBox();
console.log("Media box: %f, %f, %f, %f", mediabox.x1, mediabox.y1, mediabox.x2, mediabox.y2);
}
}
PDFNet.runWithCleanup(main);(This code finds the page size using the page's media box, which we'll talk more about in the following sections.)
To jump to a specific page with a PageIterator, call PDFDoc.GetPageIterator(page_num). If no such page exists, the index of the page will return 0. For example:
async function main() {
const itr = await doc.getPageIterator(page_num);
if (itr.next().getIndex() > 0)
{
console.log("Document does contain page#: %d", page_num);
}
else
{
console.log("Document does not contain page#: %d", page_num);
}
}
PDFNet.runWithCleanup(main);Get the answers you need: Chat with us