Guide to Evaluating PDF.js Rendering
By Adam Pez | 2019 Sep 10

12 min
Tags
guide
pdf.js
Around 2011, a team of Mozilla engineers set out to discover whether a browser-native PDF renderer written on a web platform would allow web technologies to “subsume” PDF.
That ambition led to PDF.js. An open-source JavaScript library, PDF.js renders PDF file content into an HTML <canvas> element. Today, it provides developers one of the easiest ways to embed a basic PDF viewer in a website.
However, we surveyed 57 unique organizations who came to us after trying PDF.js. Roughly 1 in 10 (10.5%) of respondents cited PDF.js rendering accuracy as their top reason for switching from PDF.js.
To help organizations avoid the same mistakes, we’ve put together this guide to explain PDF.js rendering inaccuracies and to help you decide whether these are relevant to your project.
(For more information on other aspects like functionality and performance, read the full PDF.js guide.)
PDFs are an incredibly complex file format; this is especially so given that a PDF can be generated in a hundred different ways, all of which a renderer needs to handle gracefully.
– Developer, Linkedin
Background
PDF.js offers developers two ways to render PDF content within a website:
The Canvas Back-end
The first back-end involves using the HTML5 canvas element, which provides the underlying graphics model, supporting shapes, text, images and other graphics objects. Pages are then rendered sequentially as large static bitmap images.
But right away Mozilla found canvas did not have everything PDF needed. It was said by one developer that the API was “pretty bare” for rendering PDFs. Indeed, it did not support PDF concepts such as dashed lines, certain polygon fill rules, and many blending operations.
Mozilla also recognized that rendering vector-based PDFs as large static images was inherently problematic. A separate HTML text overlay would have to be built to enable text select, text search, and copy/paste. Moreover, they would have to manage memory and image-quality issues, especially when users printed or interacted with (i.e., zoomed into as well as scrolled and panned across) a large, complicated page.
The SVG Back-end
To overcome canvas’s shortcomings, an SVG (Scalable Vector Graphics) back-end was conceived shortly after PDF.js’s inception and later added to the demo viewer. Instead of representing PDF content as large canvases, the SVG backend would represent it as compact and precise vector information, and help improve printing quality, text selection, and document accessibility.
In theory, anyways. Just like canvas, SVG was not fully compatible with the PDF graphics model. For example, SVG did not support many PDF blend modes or efficient monochrome compression, used for scanned business documents, manuals, and faxes. And adding these features would be considerably time-intensive and challenging.
The open-source community still considers the SVG back-end experimental and far from being production-ready. Thus today it supports fewer features than canvas. It is also reported to be slower in practice, particularly when scrolling complex documents.
Since the canvas back-end is more popular and complete than the SVG today, it will be the focus of the remainder of this guide.
Rendering Feature Support
Font Conversion
Many PDFs embed their fonts, used to draw text on the page. However, the format does not require that documents embed their font information in the file, and thus many PDF creators will not embed fonts.
Where PDF.js encounters a missing, non-standard, and/or malformed font, it must fall back on the local system. Fonts may thus render slowly (e.g., on iOS) or fail to render legibly:

PDF.js rendering

Correct rendering
Some text may acquire ugly spacing or kerning:

PDF.js rendering

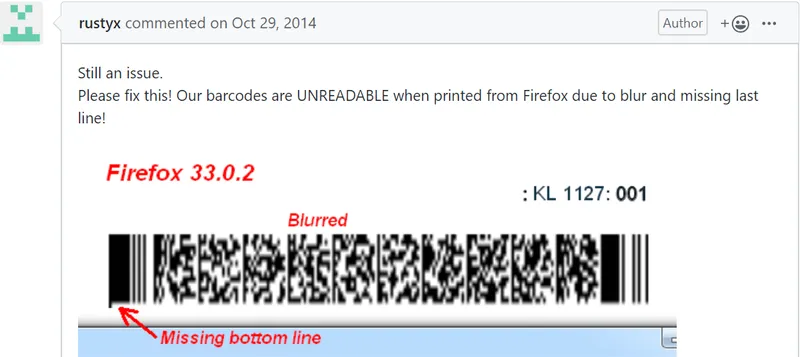
Font issues can also produce barcodes that can no longer be scanned:

PDF.js rendering

Correct rendering
If you can’t guarantee that your PDFs will contain well-formed, embedded fonts, you may need to assess the risk of incorrect font conversion. Unfortunately, with hundreds of thousands of different PDF generators — of varying quality — there’s no easy way to quantify the percentage of PDFs this risk applies to.
Image Conversion
PDFs can embed many non-JPEG image formats such as JPEG2000 and JBIG2 — common in documents within archival, biomedical, scientific, geospatial, surveillance, and industrial workflows.
However, most browsers do not natively support image compression formats other than JPEG, PNG, and GIF.
As a result, PDF.js must rely on JavaScript decoders (e.g., jpx.js) developed or imported by the open-source community to convert alternative image compression formats. These decoders don’t always get the conversion right, however, and thus some images may not display correctly — or at all:

PDF.js rendering

Correct rendering
A broken PDF shared on the PDF.js GitHub. Issue related to a JPX decoder fault.
If your users open documents generated with arbitrary software, you may have to consider the risk that some files contain alternative image compression schemes, and these may not render properly with PDF.js. Unfortunately, there may be no easy way to quantify this risk as well.
Blend Modes
Blend modes are part of the PDF specification that control how different color layers in a document will “blend” together. These can be used to create a variety of useful effects such as transparencies and will appear in PDFs such as design documents, brochures, annual reports, and textbooks.
A test document provided by the Ghent Workgroup, an international body of design artists, shows what blend modes PDF.js currently supports. You can try this yourself by opening the test document in the PDF.js demo viewer.
The following images represent test objects shown in PDF.js and used to evaluate whether it supports specific PDF rendering features. Test objects marked with a clear “X” represent a failure of the specified feature.
For example, here is the section for basic blend modes. PDF.js is shown to support all but one:

However, the same document shows PDF.js does not support blend modes applied to knockout transparency groups:

And those using Isolation:
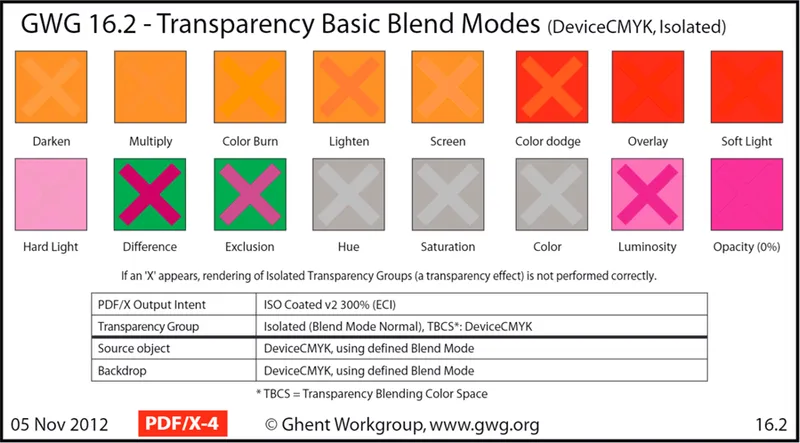
Where a blend mode is not supported by the viewer, formerly transparent layers may conceal underlying content — even text.
Here’s another open PDF.js issue related to a missing blend mode in Internet Explorer:

PDF.js rendering
Correct rendering
Missing blend modes or other missing rendering features are fine if you can be certain that your end users will only ever view very simple PDF documents. However, your users may want to view documents such as textbooks and brochures containing more advanced features within the PDF specification.
Patterns and Gradients
Patterns and gradients are another complicated part of the PDF specification. Patterns can be used to create certain textures, such as weaves, brick walls, sunbursts, and so on. Shadings can be used to produce different gradients via complex blends using math and interpolation.
For example, Axial Shadings define a color blend along a line between two points, whereas Radial Shadings define a color blend that varies between two circles. Shadings and patterns both contain a lot of parameters within the PDF specification to provide precise control over the effect.
But during a 2014 presentation on PDF.js, it was said by one developer: “I don’t think we’ll ever add support for some of the [patterns and gradients] that PDF supports, because they’re really kinda bizarre.” (20:27) The open-source community has since chipped away at the problem. Gradient and pattern support has improved from where it was several years ago when we first wrote about the issue in a 2015 blog. However, support is still incomplete, as testified by 29 open issues related to shading patterns on GitHub today.
As a result of missing patterns and gradients, some documents may display with subtle errors — such as this Imodium company logo with an incorrect gradient on the “O”:

PDF.js rendering

Correct rendering
Other inaccuracies may be much more overt as well as browser-specific, such as this issue on Firefox:

PDF.js rendering

Correct rendering
Gradients and patterns are pretty common throughout documents such as graphics-heavy annual reports as well as flyers, brochures, and other design documents in marketing and pre-print workflows. If your users work with any of these documents, it will be difficult to ascertain whether PDF.js can render their patterns and gradients as intended.
Soft Masks
Soft masks (i.e., Smask object) are another part of the PDF specification that lets you overlay images and create advanced transparencies with more control than normal image masks. You can have one image show through onto another to create impressive Photoshopped effects and designs in documents such as textbooks, brochures, and so on.
There are currently 10 open issues on GitHub today related to soft masks — including documents with missing elements and wrong colors, or obscured text. And unreliable support for soft masks may make some documents unuseable as crucial content may be covered up:

PDF.js rendering
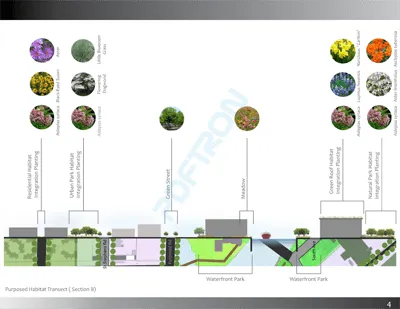
Correct rendering
(Above) Textbook Document in PDF.js issue 6967 related to a Soft Mask
Many common documents contain softmasks. However, while PDF.js supports the feature, rendering of softmasks may prove unreliable because of varied support across the browsers. It may be difficult to predict whether soft masks in your documents will render correctly for your users.
OCG Layers
Some documents (such as an intricate CAD-based PDFs) will require toggleable visual layers in order to be readable. However, PDF.js does not support OCG layers. Since it cannot access layers, PDF.js may also attempt to render every layer in documents (even layers switched off by default) contributing to performance and readability issues. Layers are sometimes present in other documents as well.

PDF.js rendering
Correct rendering
If your users are opening large and complex documents, especially CAD-based or Geospatial PDFs, PDF.js will be unable to render their documents correctly.
Color Management
PDF.js colors are rendered in an RGB format. Therefore, documents in CMYK and CMYK JPEGs require conversion.
However, colors may be too intense or simply wrong as PDF.js often does not get the conversion right due to the absence of color management features.
ICC Color Profiles
ICC color profiles, an ISO Standard, ensure colors look the same when displayed cross-platform and when printed. However, PDF.js does not support any ICC color profiles (an open issue for six years).
The following ICC test document allows you to evaluate a viewer’s support for color standards. Documents that support ICC profiles will render the image flawlessly; whereas documents that do not support the latest version of the standard will render one or more quadrants with distortions — as seen beneath:

PDF.js rendering

Correct rendering
(You can download the test document here if you want to see it in a web viewer first hand.)
If your users require a high degree of color accuracy when viewing or printing, such as in marketing collateral review & approval workflows or print settings, PDF.js poses significant risk.
Overprint Simulation
Overprint is the process of printing one color over another so that they “blend” together. It is commonly used as a production tool in pre-press design such as when one wants to apply spot colors to CMYK-color documents. (For a quick visual guide to overprint, watch this video.)
Without overprint, no color mixing will occur; the topmost colors 'knocks out' the others by default, which will cause documents to not print as intended.
Since PDF.js does not render CMYK directly, it must simulate overprint, which uses CMYK. However, PDF.js does not support overprint simulation (an open issue on GitHub for three years).

Overprint section on Ghent Workgroup test document displayed with PDF.js
Without overprint simulation, users in design agency settings, packaging and marketing workflows may find that PDF.js is unable to meet their requirements.
Zoom & Image Quality Issues
PDF.js must render content for a page onto a single large canvas as PDF.js does not support PDF tiling, which would allow PDF.js to render only displayed content. (Canvas tiling has remained an open feature issue on GitHub for four years and without a clear resolution timeline.)
When a user zooms in, therefore, PDF.js must work within the same large image; it may also have to re-render the canvas at an even larger size to achieve the required resolution. However, large canvases consume a lot of memory, and if a canvas would be too big, PDF.js is forced to fall back on the browser to re-scale the page image. The result is as you can see — blurriness on some complex documents that makes it hard to read text or perform accurate measurements.
PDF courtesy of ELEMENTAL. You can download the drawing if you wish to view it firsthand in the PDF.js demo viewer or another viewer.
Users may find PDF.js zoom unable to reach the required image depth and definition, especially for CAD-based PDFs and maps, and some scanned archival documents. Image quality issues may also hurt the UX by placing a slight blur on text and images, making it harder to read details in documents with big pages and small print. Barcodes and QI codes may also become blurry so that they can no longer be scanned when printed.
Unfortunately, due to the absence of canvas tiling as well as other issues, PDF.js will be unable to meet the requirements of those who put a premium on a high-quality UX including crisp legible text and other visual content, whether printed out, on a large single page, or at a high level of magnification.
Where PDF.js Faces the Most Rendering Issues
To help understand where PDF.js faces the most rendering difficulty today, we focused on the 31 open issues related to “broken” PDFs — issues on the GitHub forum pertaining to documents that render incorrectly with PDF.js.
Some of these shared PDFs are synthetic (i.e., test documents specifically created to capture problematic behavior). Most, however, are “organic” documents often produced in organizational workflows and shared in hopes of improving PDF.js rendering.
While not representative of all PDF.js rendering issues, these open document issues provide a rough sample of some known problems. Here is the breakdown:
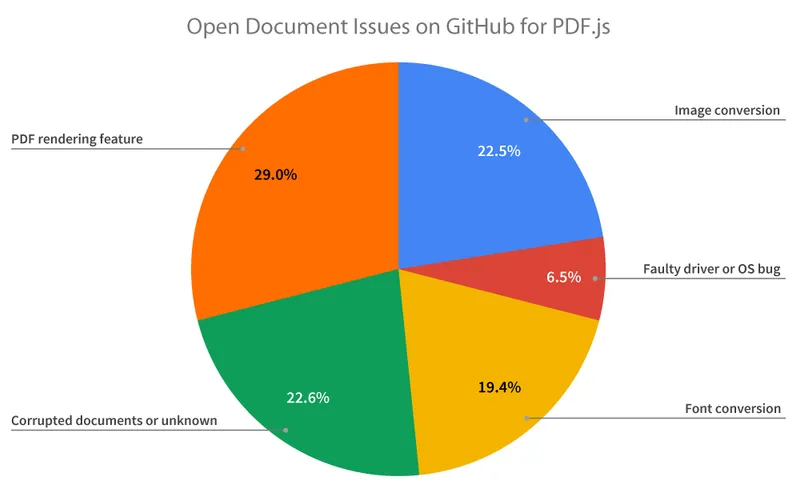
Twenty-nine percent (29%) of document issues related to a PDF rendering feature. That could be a mishandled soft mask or blending — or a missing shading or pattern. Another 22.5% and 19.4% of document issues related to a problem with image conversion and font conversion respectively. Lastly, a small percentage of issues arose from a faulty driver or OS bug (since PDF.js relies on local hardware acceleration).
The remaining 22.6% of issues split about evenly between two issues: corrupted or otherwise badly malformed documents — or documents where the causes of incorrect rendering were not clearly specified by contributors.
When PDF.js Rendering is “Good Enough”
You may find PDF.js rendering good enough for situations where you and your users are willing to tolerate some rendering uncertainty and/or where they work mainly with small and simple PDFs.
However, due to the uncertainty of PDF.js rendering, you may have difficulty assessing the possible impact of rendering inaccuracies on your UX.
In conclusion, PDF.js rendering will likely be good enough when:
- Users are willing to tolerate some rendering inaccuracies and blurriness
- You have control over documents before viewing. (Users are not opening arbitrary files.)
- PDFs are small and simple (e.g., invoices)
- Users work on the latest versions of Chrome and Firefox
- Colors need not be accurate
However, you want to consider a commercial PDF SDK if any of the following apply:
- The web viewer will be heavily relied upon in an organizational setting or commercial product
- Users demand rendering accuracy and precision
- UX needs to be a competitive differentiator
- You cannot optimize documents for PDF.js before viewing
- Colors need to be accurate
- PDFs include non-JPEG image formats such as JPEG2000 and JBIG2
- Users work in older browsers such as IE9 or on older mobile devices
Next Steps
PDF.js may be good enough if you require a short-term PDF solution for when your requirements are limited and users can accept occasional rendering inconsistencies, crashes, or slow performance.
If not, then you could use a more robust commercial solution, like Apryse WebViewer.
We always appreciate feedback on our blog. If you have any questions, don’t hesitate to contact us directly.